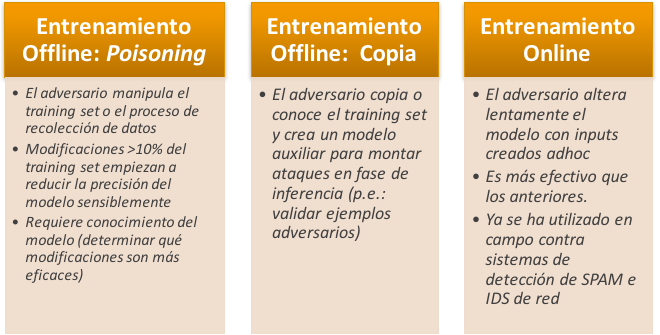
Los ataques más efectivos en esta fase son aquellos que se llevan a cabo cuando el entrenamiento del modelo se lleva a cabo online, es decir, el conjunto de datos que se utilizan para entrenar el modelo (o training set) se alimenta continuamente con nuevas muestras. En este ataque el adversario va alterando lentamente el modelo según sus intereses, proporcionando falsas muestras de entrenamiento, creadas específicamente para ese fin.
Ataques online se han observado en campo en dominios como la detección de SPAM y sistemas IDS basados en modelos de ML (“Online anomaly detection under adversarial impact” de M. Kloft y P. Laskov, International Conference on Artificial Intelligence and Statistics, 2010).
La Tabla 2, por su parte, muestra una posible clasificación de ataques a modelos de ML durante la fase de inferencia:
Tal como se muestra en la Tabla 2, los ataques a modelos de ML durante la fase de inferencia, es decir, cuando el modelo ya está en producción (entrenado y realizando su trabajo), se clasifican en dos categorías en función del conocimiento que el atacante tiene del modelo.
Cuando el atacante tiene algún conocimiento del modelo de ML que quiere atacar, hablaremos de ataques White Box. Este tipo de ataques son totalmente realistas, bien porque el atacante obtiene inteligencia sobre el modelo empleando algún otro ciberataque previo (ver los ataques de copia durante la fase de entrenamiento offline del modelo) o bien porque se empleen técnicas de ingeniería inversa sobre el modelo de ML, que son posibles porque en muchas ocasiones los algoritmos de ML entrenados en algún potente data center en algún lugar del mundo, se comprimen y se descargan a los dispositivos (por ejemplo smartphones) donde se ejecutará el software que hace uso de ellos.
Desde el punto de vista académico, los ataques a modelos de ML más interesantes son los de tipo Black Box, que son los que se llevan a cabo cuando el adversario no tiene ningún conocimiento del modelo de ML que quiere atacar.
En estos ataques hay una fase de reconocimiento del modelo, que se desarrolla enviándole inputs cuidadosamente creados y observando las salidas generadas por el modelo. Este tipo de ataque se suele denominar Ataque del Oráculo y es especialmente factible en aquellos sistemas que hacen uso de modelos de ML generados empleando soluciones de MLaaS (ML as a Service) como Amazon Machine Learning o Azure Machine Learning Service en las que el modelo entrenado se monta como un servicio web más o menos públicamente accesible.
Por el momento, el principal hándicap para que este tipo de ataques tenga éxito, es que el número de respuestas que hay que recolectar (o el número de peticiones de inferencia que hay que hacer al modelo) debe ser comparable al tamaño del training set, pero como se ha comentado antes, el hecho de que cada vez más modelos de ML se entrenen y se pongan en producción a través de servicios MLaaS simplifica esta tarea. Formalmente, el uso de MLaaS tiende a incrementar la superficie de ataque.
El adversario, armado con esta información y empleando también algoritmos de ML, calculará los llamados ejemplos adversarios, que al ser enviados al modelo de ML en producción harán que este genere una predicción errónea. A la disciplina dentro del campo de ML que desarrolla en cálculo de ejemplos adversarios para modelos de ML se le denomina Adversary Machine Learning: ML para atacar ML.
La propiedad más inquietante de los ejemplos adversarios es su “transferibilidad”, que permite a un adversario maximizar el ROI, por así decirlo, de su inversión en el cálculo de ejemplos adversarios y que, por tanto, incrementa la probabilidad de hacer uso de estas técnicas para atacar sistemas basados en modelos de ML: los ejemplos adversarios calculados para atacar un sistema basado en un modelo de ML, pueden servir para atacar a otro sistema basado en ML siempre que este se base en los mismos algoritmos de ML incluso si está entrenado con un training set distinto.
Como se recoge en la Tabla 2 las técnicas de ataque a modelos de ML conocidas hasta el momento consiguen generar ejemplos adversarios con tasas de éxito de más del 84% (nivel de confianza con el que el modelo de ML atacado infiere incorrectamente un ejemplo adversario).
Contramedidas
Como se ha comentado previamente, la disciplina de la seguridad para modelos de ML es muy reciente y la mayor parte del trabajo de investigación publicado hasta el momento, se ha centrado en identificar vulnerabilidades y posibles métodos de ataque, especialmente en el campo del cálculo de ejemplos adversarios. Sin embargo, mucho queda por hacer en lo referente a desarrollo de medidas de protección.
En base a los estudios publicados más recientemente, las mejores estrategias de protección pasan por rehacer buena parte del trabajo realizado hasta el momento en la búsqueda de modelos de ML más robustos, desarrollados con un modelo de amenazas en mente en el que el adversario juegue un papel importante:
• Recalcular los modelos de ML empleando algoritmos más complejos (por ejemplo, algoritmos no-lineales frente a algoritmos lineales) que permiten generar modelos de ML más precisos, lo que disminuye exponencialmente las posibilidades de encontrar ejemplos adversarios para un modelo. Esto no siempre es posible, ya que para una misma precisión, el entrenamiento de modelos basados en algoritmos de ML más complejos requiere training sets mucho mayores que al emplear algoritmos menos complejos. Existe pues una tensión entre la precisión y la robustez del modelo.
• Recalcular los modelos de ML con nuevos algoritmos de ML (desarrollados recientemente) que son más tolerantes al poisoning del training set.
• Adversarial Training: emplear Adversarial ML para calcular ejemplos adversarios para todos los posibles tipos de ataque conocidos contra un modelo de ML en producción y reentrenar (es decir, recalcular) el modelo incorporando estos ejemplos adversarios al training set original. Esta parece ser, hasta el momento, la técnica más prometedora, aunque no exenta de sobresalientes desafíos técnicos.
Conclusiones
A pesar de su cada vez más extendido uso, la inmensa mayoría los sistemas basados en ML se han desarrollado con un modelo de amenazas muy débil y nada realista, en el que las condiciones normales de funcionamiento suponen la ausencia de adversarios. Esto convierte a estos sistemas en vulnerables a diferentes tipos de ataques, tal como se ha documentado en múltiples artículos de investigación, existiendo además evidencia de que varios de estos ataques se han puesto en práctica ya con éxito en campo.
En el estado actual de desarrollo del campo de la seguridad para ML, parece evidente que aún están por descubrir tanto nuevos ataques como nuevas contramedidas.
Lo aprendido de la experiencia en ciberseguridad durante los últimos años nos dice que nuestros adversarios son numerosos, están bien financiados (con frecuencia mejor que los defensores), son técnicamente capaces y son especialmente persistentes cuando se enfocan en objetivos de alto valor que pueden reportarles grandes beneficios (económicos principalmente), como sin duda lo son muchos de los sistemas basados en modelos de ML. ¿Cuánto podría pagar por un conjunto de ejemplos adversarios que fueran capaces de engañar a un sistema de reconocimiento facial que diera acceso a determinado recurso? ¿Y un ejemplo adversario que contenga una carga maliciosa que pudiera engañar a un sistema de protección anti-malware de última generación basado únicamente en modelos de ML?
De todo esto lo expuesto en este artículo se puede concluir que, lamentablemente, la amenaza a la integridad y la disponibilidad de sistemas basados en modelos de ML es real y que lamentablemente, como en muchas otras ocasiones en el pasado, esta amenaza se está infravalorando, sino ignorando completamente, en muchos casos de uso.
En este tiempo de popularización del uso de ML, se hace necesario también analizar la calidad y la robustez del modelo de ML que sustenta un sistema, exigiendo a los fabricantes información que permita evaluar la robustez del modelo de ML tales como:
• Detalles sobre el tipo de algoritmo de ML utilizado
• Métricas de rendimiento del algoritmo (precisión en las predicciones)
• Detalles sobre el tamaño del training set
• Detalles sobre si implementan algún mecanismo que incremente la robustez del algoritmo frente a ataques como por ejemplo los basados en ejemplos adversarios o en poisoning del training set.
Hasta que el campo de la seguridad para ML alcance un grado de madurez aceptable, debemos asumir que los sistemas basados en ML tienen más limitaciones de las que se han considerado generalmente: funcionan correctamente en general, pero pueden romperse con relativa facilidad en presencia de adversarios. Esto implica que, si bien ML puede usarse como mecanismo complementario en sistemas centrados en la detección o la toma de decisiones, aún no es seguro usar esta tecnología para reemplazar totalmente otras técnicas de detección y análisis tradicionales, incluyendo su supervisión directa por seres humanos.